1.1 The command window
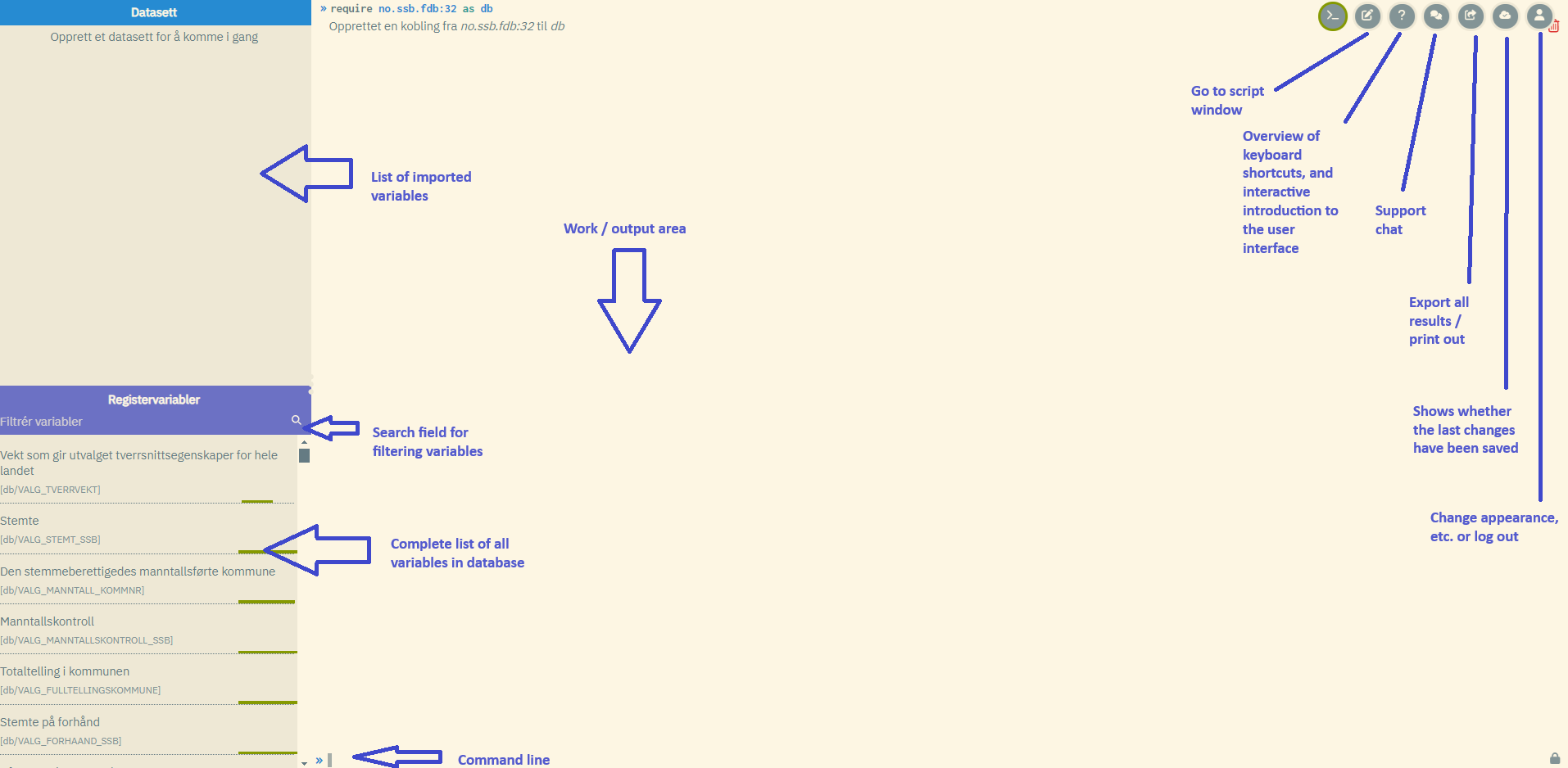
The command window consists of the following:
- Work area (largest space at the far right)
- Overview of available variables (area at the bottom left - this space is blank until you have connected to a data bank by using the
requirecommand, ref. section 2.1) - Overview of variables imported into own datasets (area at the top left)
- Command line (bottom of work area)
Custom datasets are built up by importing, processing and developing new variables based on variables from the data bank. Datasets are stored in the user's command window and do not disappear without the user deleting them. See section 2 on how to create datasets and import variables.
After the command window has been filled up with imported variables, it may look like this:
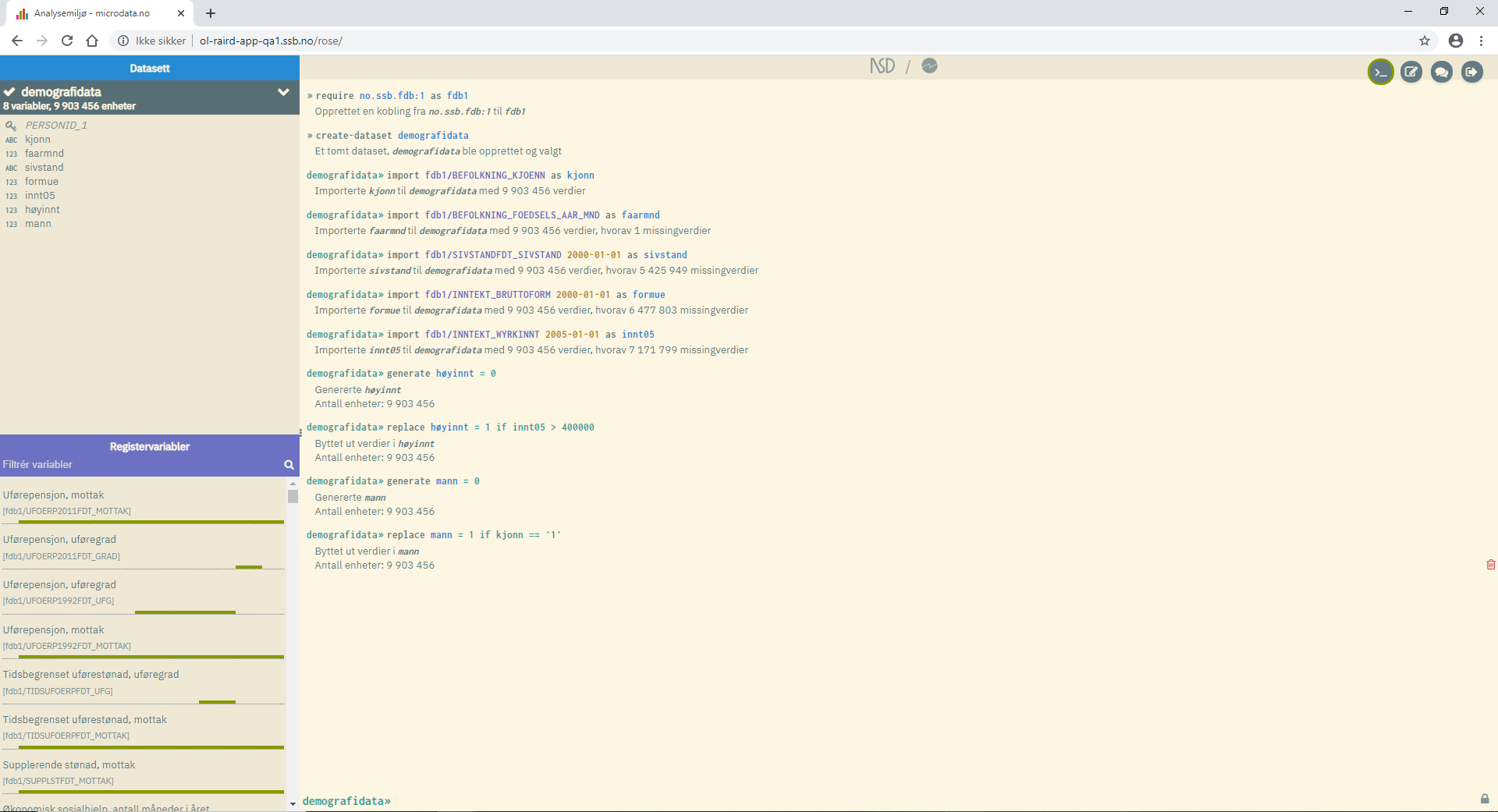
In the example above, a dataset named "demografidata" ("demographic data") has been created, containing 8 variables and 9 903 456 units (individuals). Amongst the variables, you will find the personal identification key PERSONID_1. This is a system variable that is always included with the import of variables. It specifies a unique person identifier that is used as a key for linking variables together on individual level. The system performs an automatic merging of variables according to the "left join" principle, so if you are only interested in using data on individual cross-sectional level, then you do not need to deal with this variable1.
The work area displays a log containing the commands that have been executed and the resulting response, be it tables, figures and other feedback.
To indicate that the user is now working on the dataset "demografidata" ("demographic data"), demografidata>> is
now displayed instead of >> at the bottom (command line). If
multiple datasets are created, the window at the top left will contain
several variable views correspondingly. To work on different datasets,
one can switch between them by using the command use <dataset>. The
leading text in the command line will indicate what dataset the user has moved to.
Footnotes
-
The PERSONID_1 identification key only needs to be specified explicitly in cases where the
collapsecommand is used to aggregate information from a sub-individual level up to the individual level. A typical example is when you use theimport-eventcommand to create a dataset with "events" as unit type (see section 2.3.2). In practice, this data set, which can contain several value measurements per individual, is represented by separate data records that point to the different values (all value measurements between two dates are imported for a given variable), and cannot be easily linked to other data sets. In order to be able to link data based on event information (import-event) with ordinary individual-level datasets, one must use thecollapsecommand to aggregate the data up to the individual level and then use themergecommand (see sections 2.8 and 3.4). Another example of sub-individual data is so-called course variables (data on ongoing studies) which can contain several value measurements per individual even at cross-sectional level (import), since it is possible to take several studies at the same time. ↩